
Case Study: Building a Data Pipeline to Recommend Health-Conscious Skincare Products to Consumers

For just over one year now, I’ve been working in the data field as a consultant, primarily developing my data engineering skills. As I learned more about data warehouses, cloud technologies and business intelligence at work, I felt a need to invest my time into some formal training which I believe would further supplement my on-the-job training. As I was searching for courses and books online, I stumbled across Correlation One’s ad for their brand new and completely free program: DS4A/Data Engineering. I had previously participated in the first cohort of Correlation One’s Data Science for All/Empowerment program, which I found to be a rewarding experience, so this news came to me in an email at the most opportune time and I had to try to enroll in this program. I applied for the program in February and was selected to be a part of cohort 1. Many useful topics were covered during the program such as SQL, web scraping, exploratory data analysis, data visualization and data engineering on AWS. In addition to weekly Saturday lectures, we were given assignments to reinforce our learning which I found very beneficial. I personally like to have notes and review content so I can make sure that I’m grasping new concepts, so this format was ideal for me.
The Problem
During the program, participants were grouped into small teams to collaborate on a data engineering capstone project that would put nearly everything we had learned into practice. Many of us were interested in doing analyses and building machine learning models, but the goal of the program was to focus more on data engineering, so deciding on an initial topic was a challenge for our team. However, after brainstorming and making a list of our interests and general problems that we wanted to solve, we decided to build a data pipeline that would contribute to self-care and overall wellness. Thus, we decided to recommend health-conscious skincare products to consumers. In our research, we discovered that the problem that we wanted to solve would be threefold:
people need to find good skin care products
some skin care products are harmful to humans and the environment because of their ingredients
there is no convenient way to immediately learn about a product’s impact while shopping
We learned that several skincare products on the market contain chemicals that are known to cause cancer, acute diseases, chronic diseases and environmental degradation. This is a problem that my team and I deemed worthy to solve using our data engineering skills, both previously and recently acquired. We set out to build a data pipeline that enables recommendations of health-conscious skincare products to consumers. Our team defined a “health-conscious product” as a product that does not contain any ingredients that are harmful to human and/or environmental health. These are the only types of products we wanted to compile and recommend to users, and we recognized that before we could build the recommendation engine, we had to build a well-structured data pipeline and warehouse.
Method
Data Collection
To embark on the journey of creating the data pipeline, we first had to acquire the data that we needed to address this issue. We needed to find data about products, their ingredients, the harmfulness of ingredients and user purchases. We knew that we had to use multiple sources to find this data, so step 1 was simply to collect data. The first dataset contained historical user data for a list of skincare and make up products. The dataset included user features such as skin tone, skin type, eye color, and hair color. The creator of this dataset scraped Sephora.com using selenium webdriver and uploaded it to GitHub. The second dataset, created by a different researcher, was also scraped from Sephora’s website using beautiful soup and uploaded to Kaggle. The dataset contained Sephora’s inventory of over 9,000 products, although we later filtered this list to focus only on skincare products. The third dataset was a compilation of over 1,900 chemicals from the US Food and Drug Administration, US Environmental Protection Agency and the European Union Campaign for Safe Cosmetics. Since the data from the EPA’s website was in PDF form, we had to convert it into an Excel file, then convert it into a CSV file before merging with the others. The last dataset was sourced from the California Health and Human Services Open Data Portal which includes cosmetic products with ingredients known or suspected to cause cancer, birth defects, or other developmental or reproductive harm.
Data Cleaning and EDA
Step 2 was the data cleaning phase which was done using Python. Columns were created, dropped and cleaned to create new CSV files that we could work with in AWS. Since the main goal of our project was to recommend health-conscious products, we had to find a way to label products as health-conscious or not. We created a column to calculate an impact score for each product. The impact score was the ratio of the number of harmful ingredients to total ingredients per product. The higher the number the more harmful the product was. This was our primary means of determining which products we were going to recommend (i.e. those with a score of 0). After all the data preparation steps, we were able to group the data into 4 different files: User, Product, Ingredients and Product Harmful Impact.
We also explored the data to see what the general trends were. We started by doing a correlation matrix, and we defined a strong correlation as 0.7 and up while moderate was 0.5-0.69 and weak was less than 0.5. Since all correlations were less than 0.1, we concluded that there were no strong relationships between a product’s harmful score and its price or its star ratings. We initially thought that products which were more health conscious could potentially be more expensive or have better ratings than the harmful ones, but the weak correlations suggest otherwise. The database contained almost a 50-50 split between health conscious and harmful products and we learned that the harmful products could have up to 10 different chemicals that result in human or environmental damage. Since the project’s focus was on data engineering, this was the extent of our EDA, and we learned with this exercise that there were health-conscious products that we could use for our database and recommendation engine. After this, we spent most of our time on the next steps, which entailed building the actual data pipeline.
Data Loading and Building the Data Warehouse in AWS
An EC2 instance was created on AWS and we manually uploaded the clean CSV files to our S3 bucket. We used SQL in Amazon Redshift to create tables and populate them with the data from the static files. After the raw tables were created, my role was to use them to design the star schema and create the dimensions and fact tables. A representation of the star schema is in the picture below.

Figure 1. Dimensional Model
After building the fact and dimension tables, we initially wanted to connect AWS directly to Tableau for our dashboard, but we didn’t have access to the paid version of Tableau, so we had to export the files from the data warehouse to the S3 bucket as CSVs, and use them as input for the dashboard and recommendation engine.
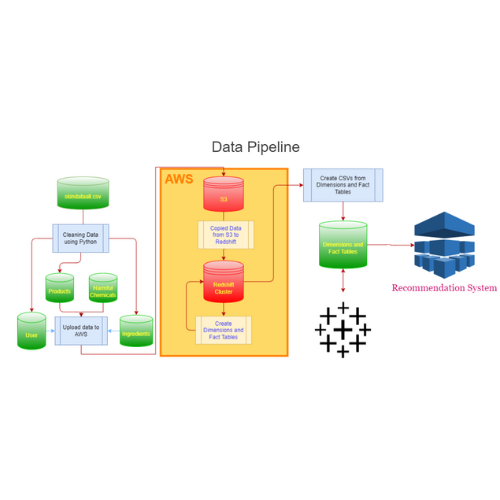
Figure 2. The Data Pipeline
Data Pre-processing
Another task which I also took ownership of was the data pre-processing before building the recommendation engine. I joined all the tables to create one dataframe to use as the input for the engine. I chose to include the relevant product features such as price & rating and exclude irrelevant features such as ids. User characteristics were also retained for the purpose of filtering to more specific results. Since we only wanted to recommend health-conscious products, I also excluded the harmful products from the dataframe. Ultimately, there was a total of 152 health conscious products from 53 different brands which were used as the basis for the recommendation pool.
Building the Recommendation Engine
After doing some research, I discovered the Collaborative Filtering algorithm, which I used to build the recommendation engine. The approach used was the item-based filtering approach whereby an item matrix was built to determine the relationships between the health conscious products in the database and infer user preferences. The engine enables users to search for products and view other suggestions, but it will also enable them to filter those recommendations based on their personal preferences and profiles. The engine works by receiving input from the user (i.e. the exact name of the product that they are searching for), processing that input by finding the product correlations via collaborative filtering, then outputting a list of suggested products with the highest correlations in addition to the product the user entered. My code for this recommendation engine is on GitHub. The two figures below illustrate that the recommendation engine starts off by showing 6 suggested products, then the user can further customize that list based on their preferences. The engine shows the product category, name, price and rating, which we considered to be relevant to shoppers. For simplicity, a sample result set was used as the input to the Tableau Public dashboard where we display the engine.

Figure 3. Recommendation Engine
Building the Front End Interface
The last part of the project was to build the front end interface where users can retrieve their health-conscious product recommendations. An interactive Tableau dashboard was built to showcase various aspects of our project, including the recommendation engine. Hovering over items at the top will reveal information about the dataset, and using the filters at the bottom will kickstart the recommendation engine.
Conclusion
The team’s goal was to build a recommendation engine that suggests health conscious self-care products to users, specifically skincare products. In order to do that, we had to ensure that we went through the data engineering process to ensure that we had good data to use as input for the engine. Our solution created an easy way for individuals to find good skin care products that are not harmful to them or the environment. This solves the problem that we originally wanted to address. There are many things that could be done to expand on the project such as upgrading the engine to work with partial product searches among many other things. However, these would be the goals of a data scientist. This project shows that we could build an end-to-end data pipeline that optimizes and prepares data for others to analyze, build models or, in this case, build a recommendation engine. In the end, our team won one of the top 3 crowd favorite awards, and we couldn’t be prouder of all the effort everyone put in to create this project!